

查看今天的最新新闻,矿工如何赚钱

今天我们带大家参观【比特币交易网络】的市场版块。 下面我们就来了解一下最新的数字货币行情并进行分析。
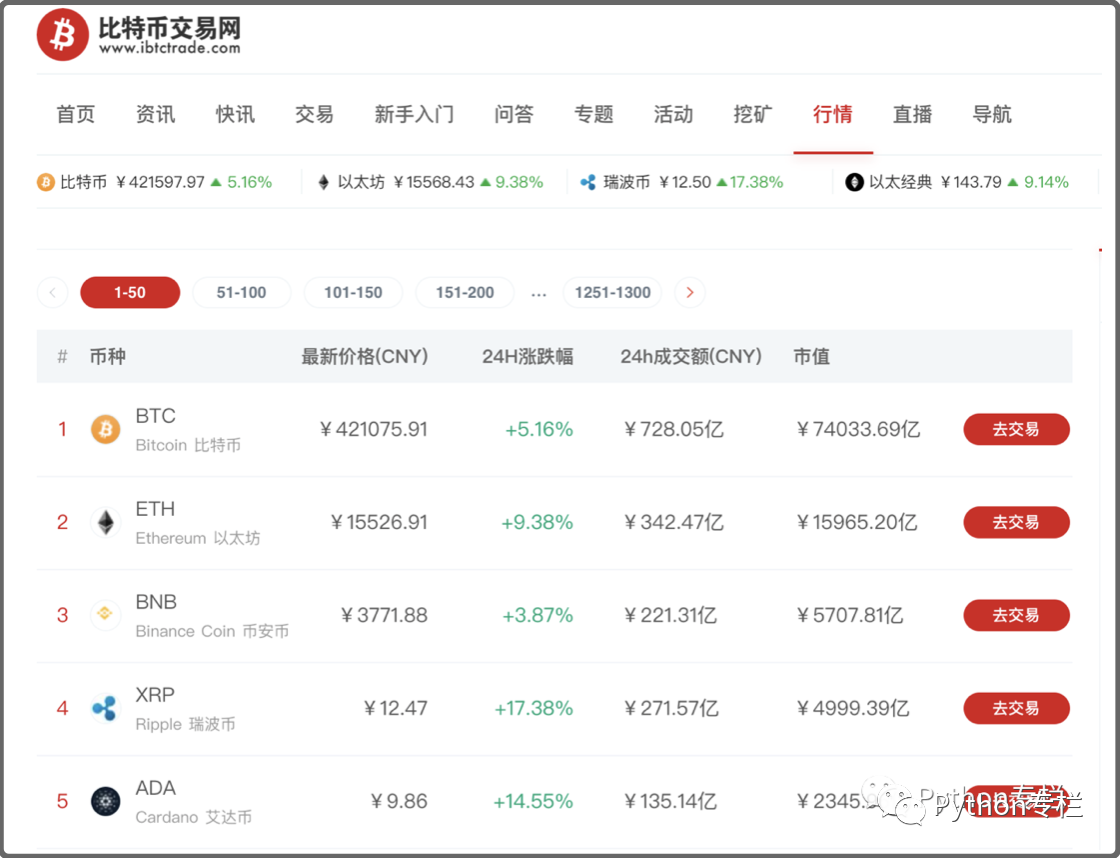
本文将帮助您爬取最新的数字货币交易信息并进行一定的数据分析。
我们的数据分析:
第一部分:爬取数据
按照我们之前介绍的步骤爬取数据:
获取url及url分页规则
首先我们得到的是【比特币交易网络】市场版块的首页链接:
接下来我们来分析一下分页的规则如下:
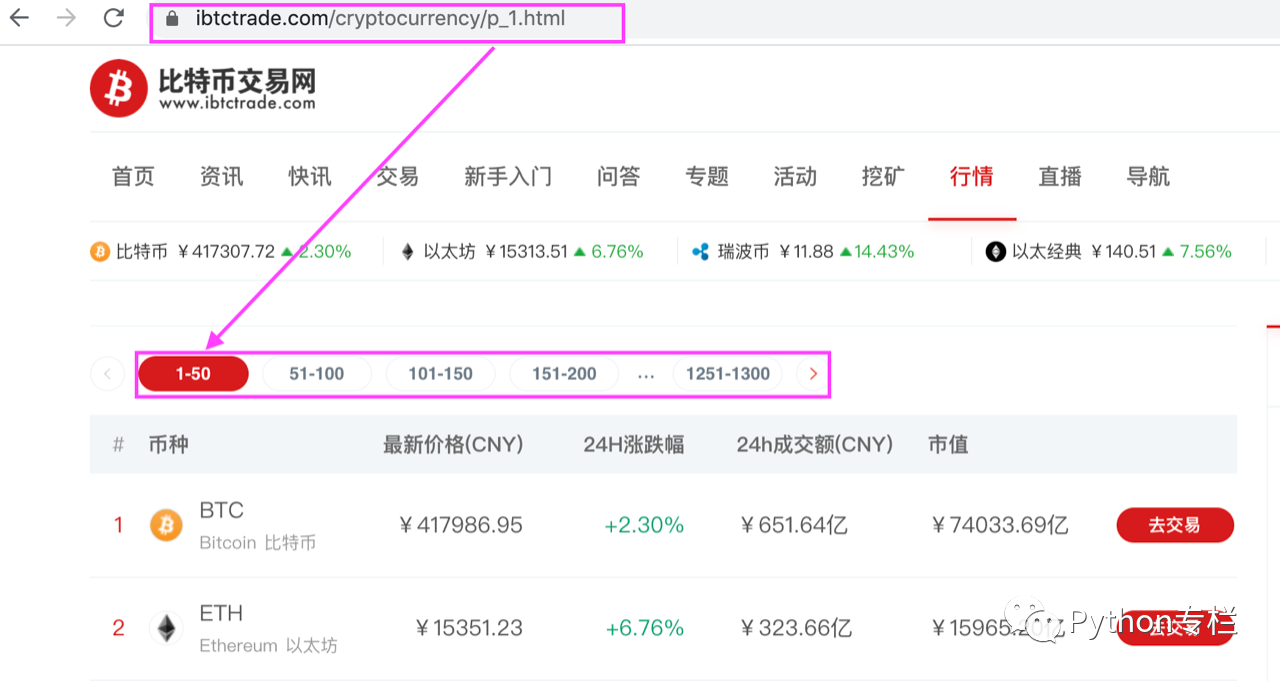
所以我们知道链接的结尾发生了变化。 第一页是p_1,第二页是p_2,……所以我们只需要在for循环中改变页码后面的值即可欧意交易所,所以代码:

如果想要获取更多的数据欧易交易所,可以在range函数中设置更大的范围。
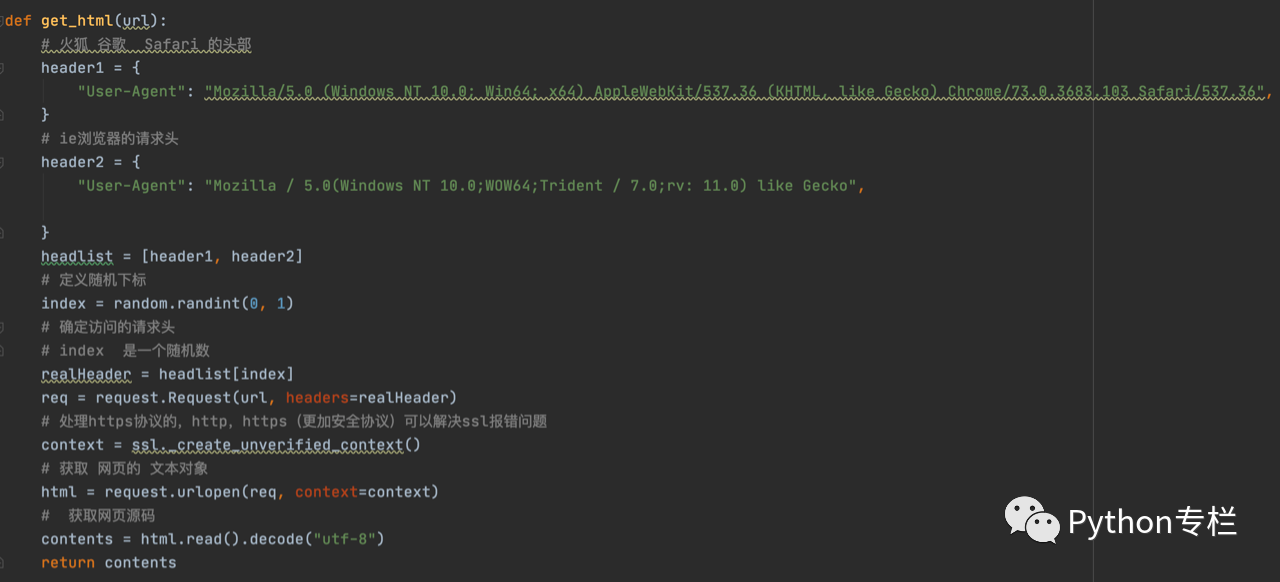
发送请求[可以使用or]
有了url,我们就需要进行下一步,开始使用它或者发送请求。 具体使用方法请参考【20天学会爬虫】内容部分。 我们仍然封装一个名为(url)的函数,它有一个参数,就是我们上一步中的url路径。 代码如下所示:
调用上一步的for循环中的函数
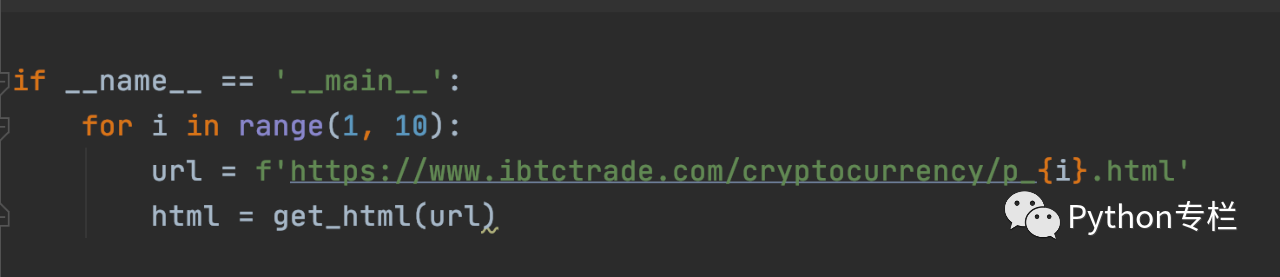
注意:一开始只能测试一个页面抓取是否成功,然后添加循环,否则很容易被阻塞。
获取响应对象中的数据
经过测试,我们发现确实可以获取到每个页面的内容。 这时候我们就开始分析页面,解析里面的数据。
通过F12进入开发工具页面,分析我们需要的数据的位置。 发现所有内容都在一个class=的div中,每个a标签代表一种货币。
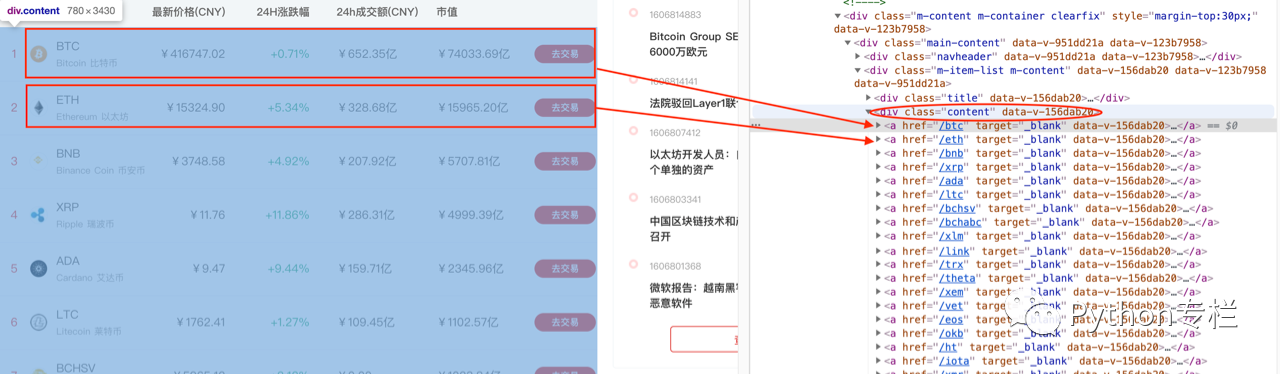
您可以展开a标签继续分析每个数据所在的标签。
现在我们了解了页面的结构,我们可以解析它了。 定义了一个(html)函数,参数是我们上一步获取到的html内容。
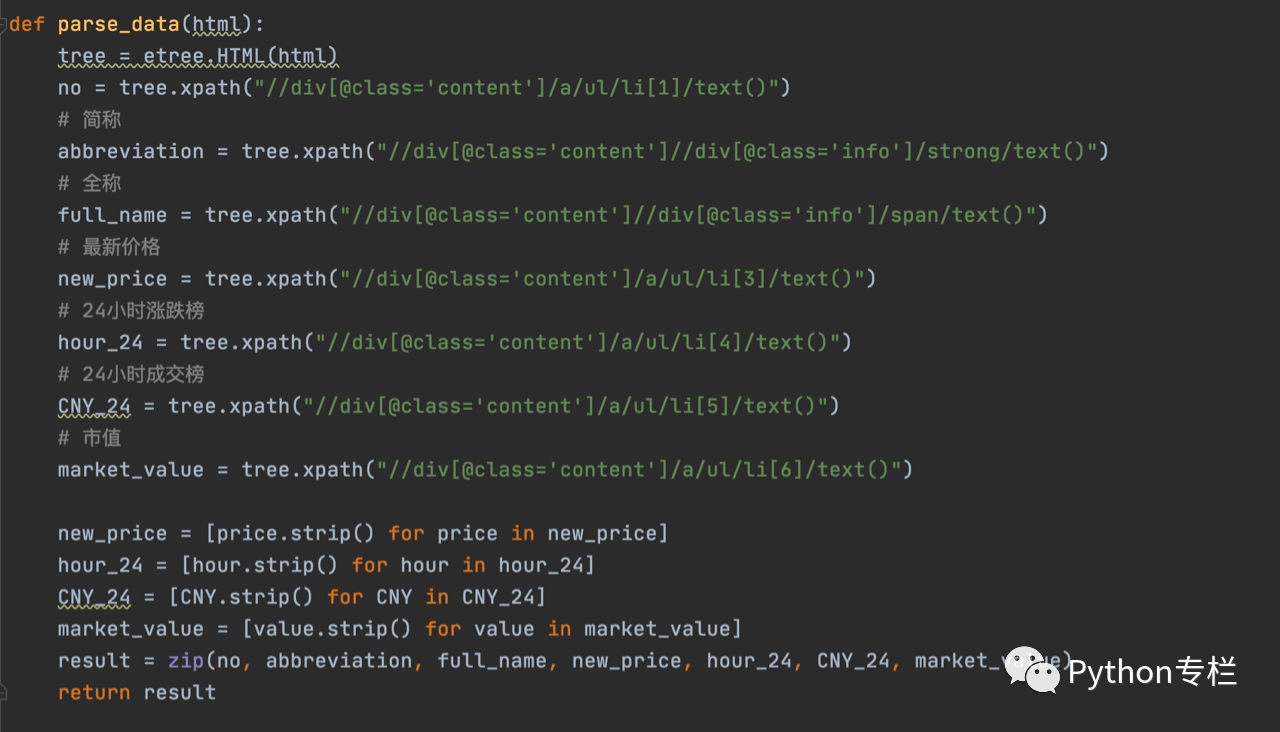
其中,我们在解析函数中得到的24小时价格涨跌列表中含有空格和换行符,所以我们需要使用列表推送的方法将空格和换行符去掉,然后调用解析函数:

数据持久存储
最后一步就是持久化存储我们解析出来的数据!使用with+open()函数来保存数据

提醒大家,最后还是要调用main中的(data)函数。
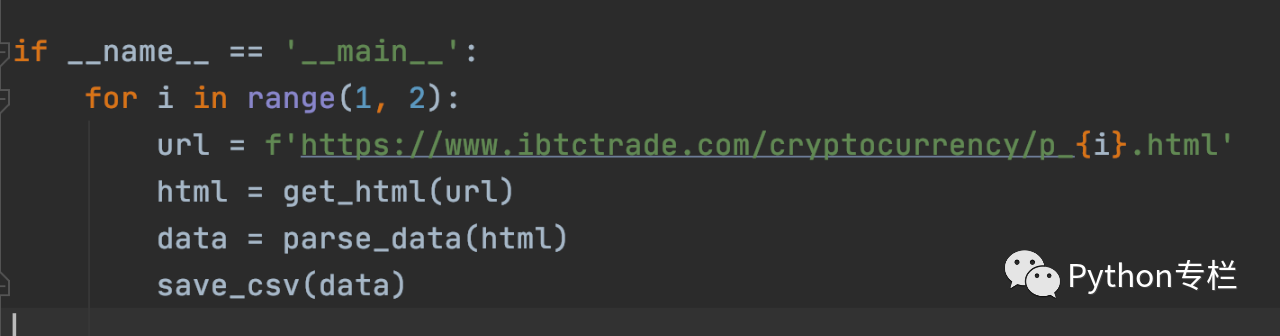
这个可以吗? 不! 因为循环速度太快,很容易让对方发现你是爬虫,所以可以使用time.sleep()进行延迟处理。 代码如下:
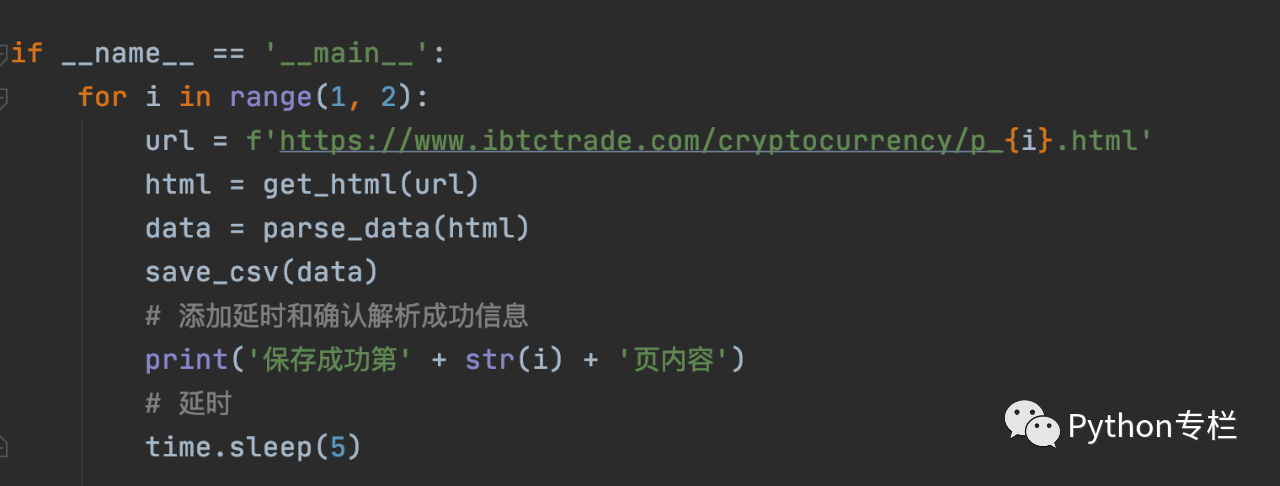
至此,我们的爬虫内容就完成了。
第二部分:数据分析部分
现在我们有了数据,让我们开始分析吧!首先,创建一个新文件并导入所需的包

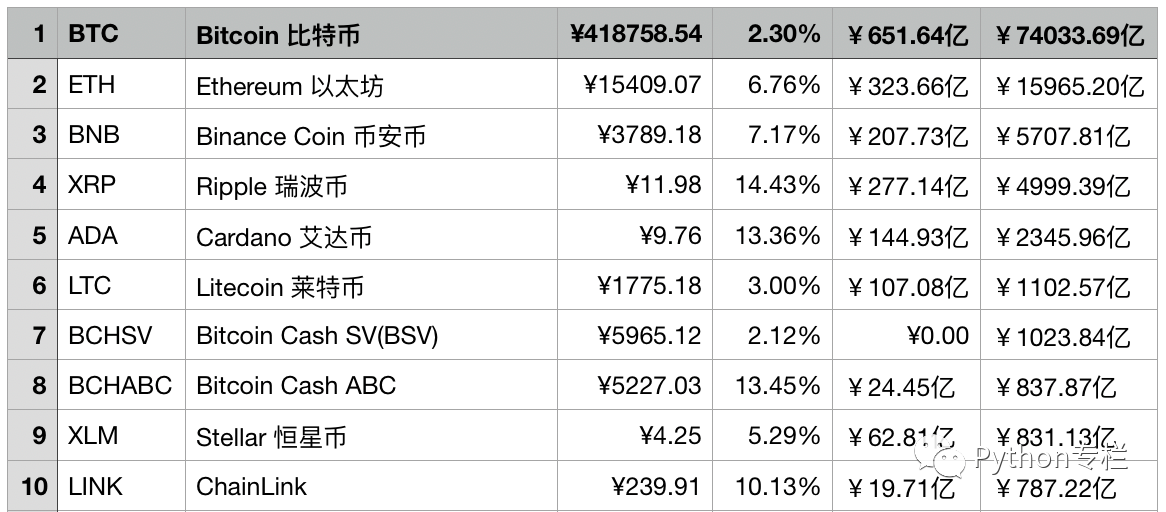
读取数据并设置数据的列名,使用data.,查看添加的前5条数据,使用head()
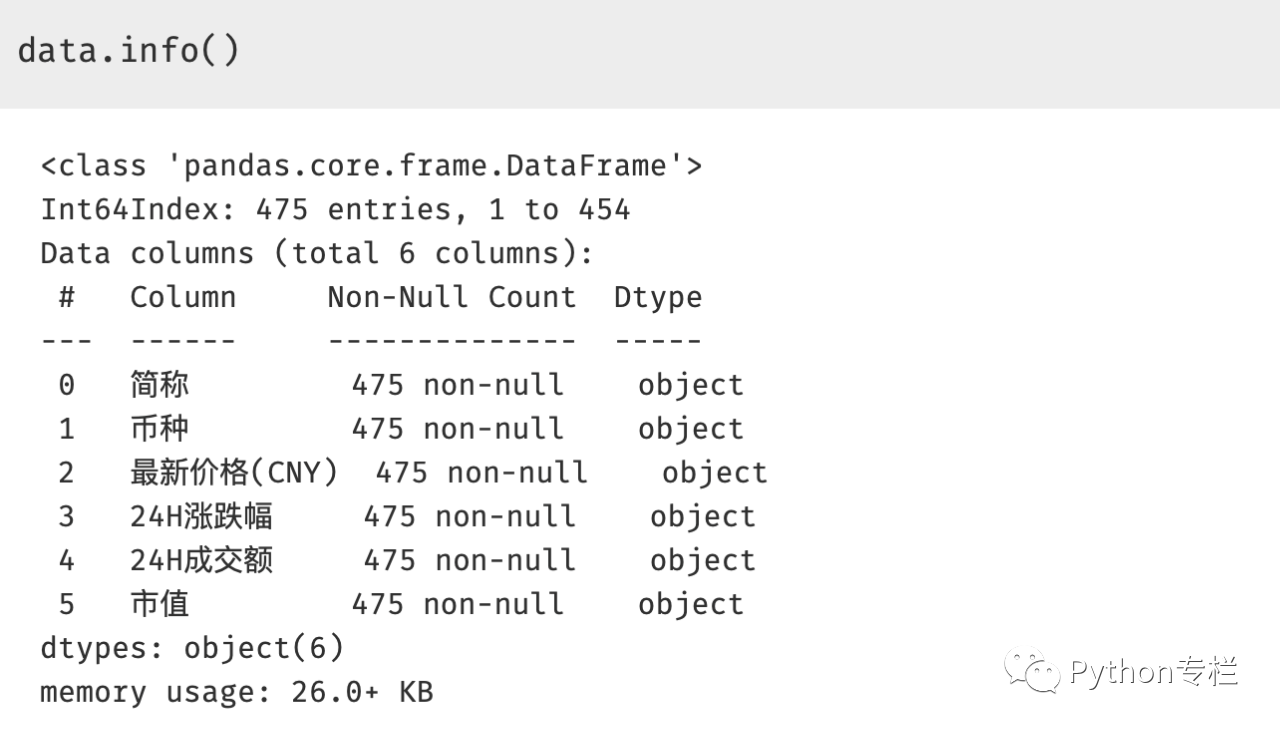
为了理解数据的结构和数据类型,我们需要看看使用 info()
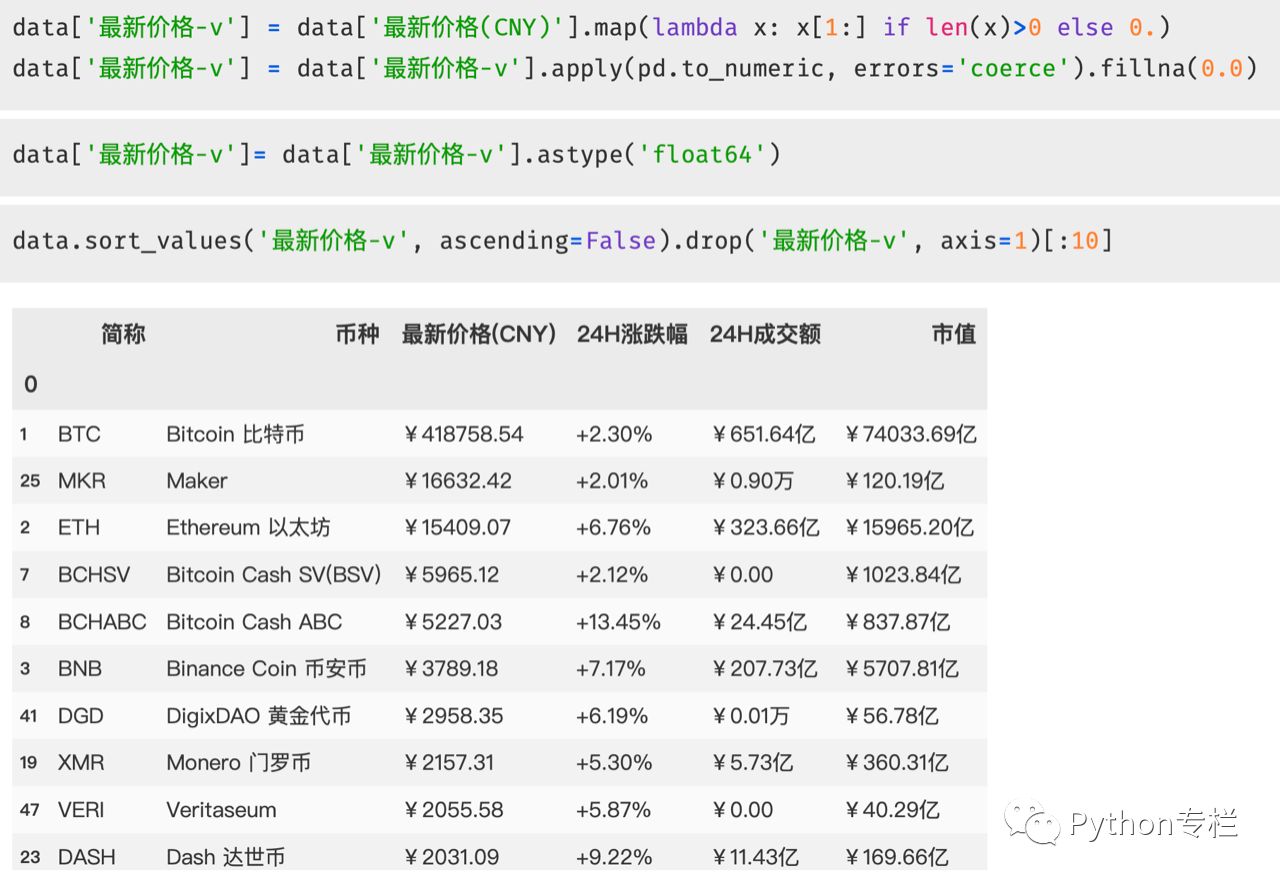
成交价格前10名榜单
接下来我们开始获取最新交易价格的前10名列表,但是我们通过info()检查的数据类型都是,如果我们需要对最新交易价格进行排序,我们需要将其数据类型更改为数值类型。 现在有[¥]符号,我们需要在转换之前将其删除。 另外需要注意的是,成交价格中有[-]的情况也必须处理。 这是我们数据清理的一部分。 将 [-] 替换为 0

在我们的分析阶段如何实现这一点? 我们需要使用匿名函数和map的组合,还需要进行类型转换。 虽然此时提取成功,但是类型还没有转换成功。 我们需要转换为float类型。 所以使用('type')来进行处理。
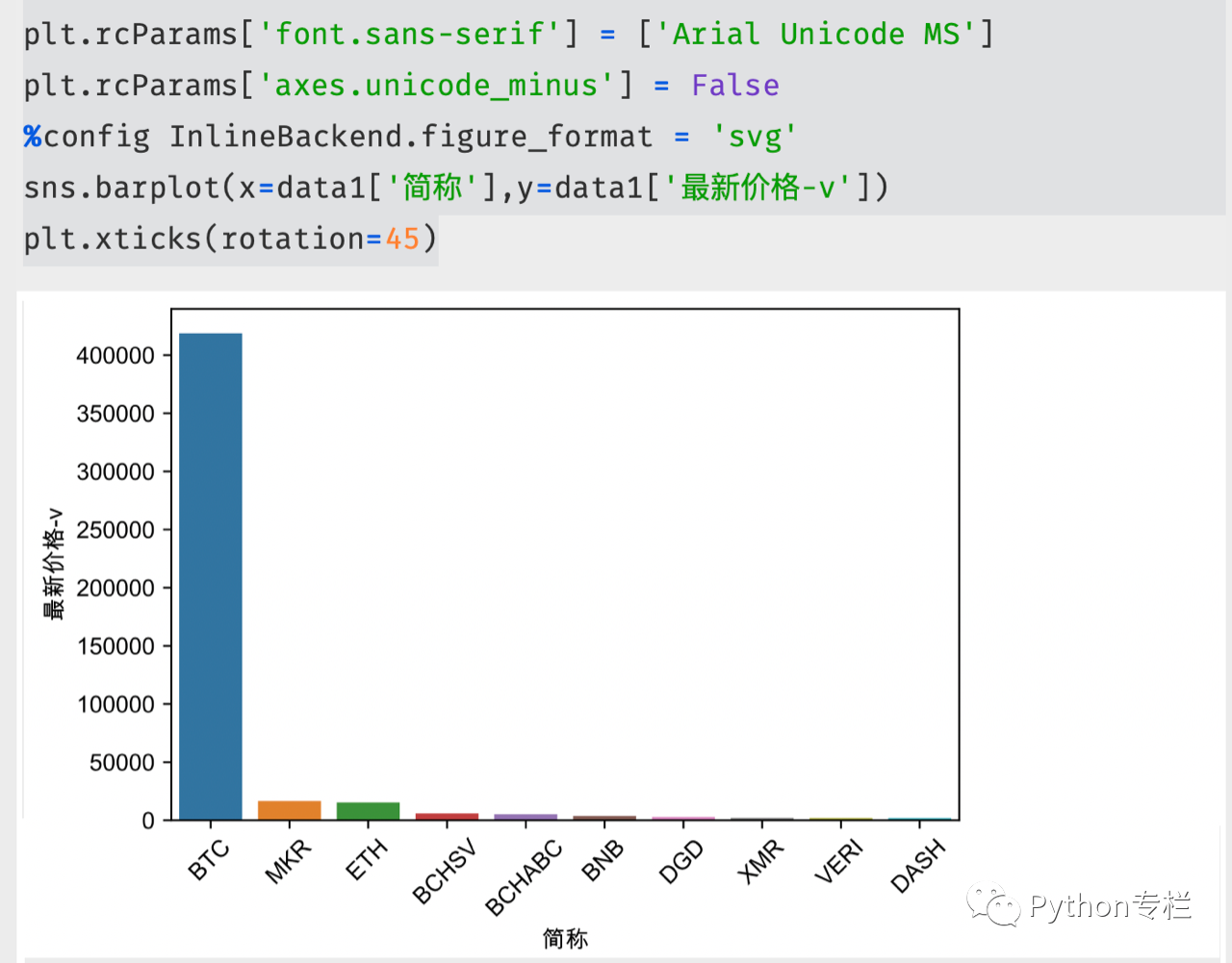
此时我们就可以直观地展示这些数据了。 注意中文乱码问题。
24小时收益榜
我们还需要处理24小时增益列表的数据,因为我们知道该列是类型的,有[+]和[-]列表。 我们需要找出[+]的币种,然后进行%处理。

条形图显示:
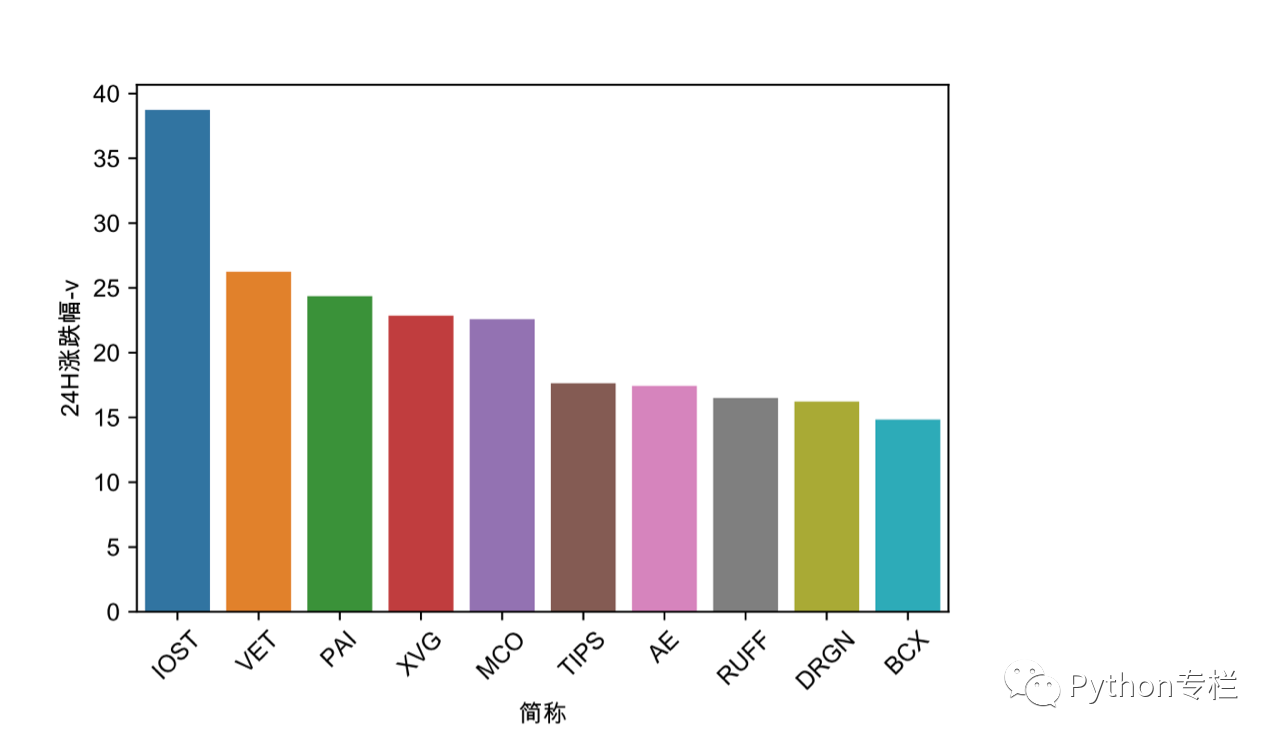
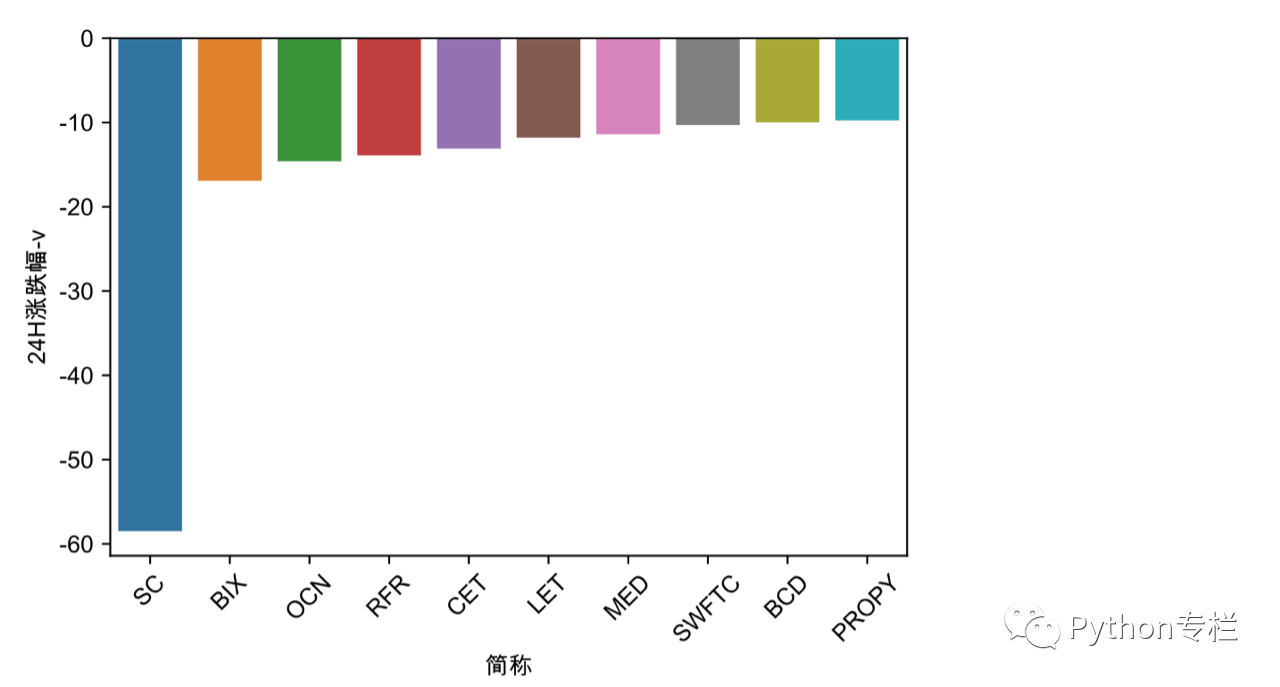
24小时拒绝名单
了解了增加列表之后,我们再来看看减少列表的处理

画面显示:
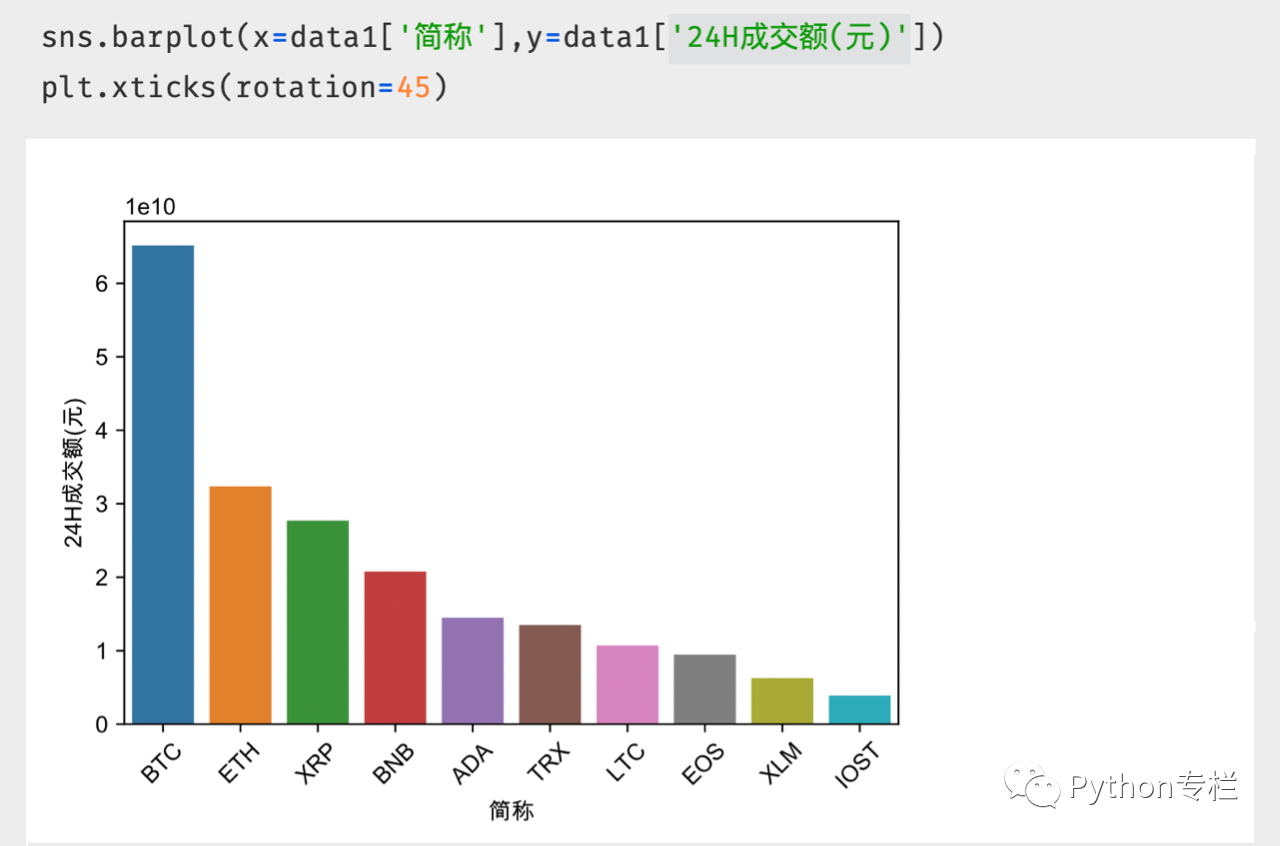
24小时成交额前十榜单
大家仔细观察我们的交易额,发现交易额都是【亿】、【万】,而且还有一个【日元】符号。 那么我们如何处理这样的数据呢? 大动作来了~~~

我们定义了一个()函数来处理单位问题和[¥]符号问题。然后进行可视化处理
当然还有很多内容我们还没有给大家展示,你们还期待什么呢? 请留言、点赞并收藏!
网友评论